Container Attached Storage (CAS)
In CAS or Container Attached Storage architecture, storage runs within containers and is closely associated with the application that the storage is bound to. Storage runs as micro service and will have no Kernel module dependencies. Orchestration systems such as Kubernetes orchestrates the storage volume like any other micro services or container. CAS provides benefits of both DAS and NAS.
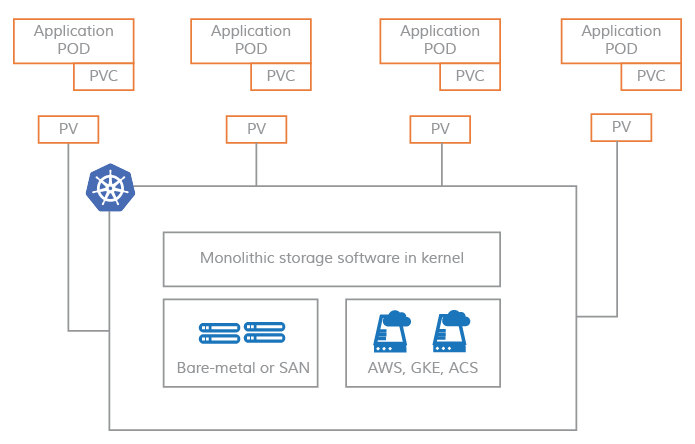
PVs on monolithic systems
In non-CAS models, Kubernetes Persistent Volumes are still tightly coupled to the Kernel modules, making the storage software on Kubernetes nodes monolithic in nature.
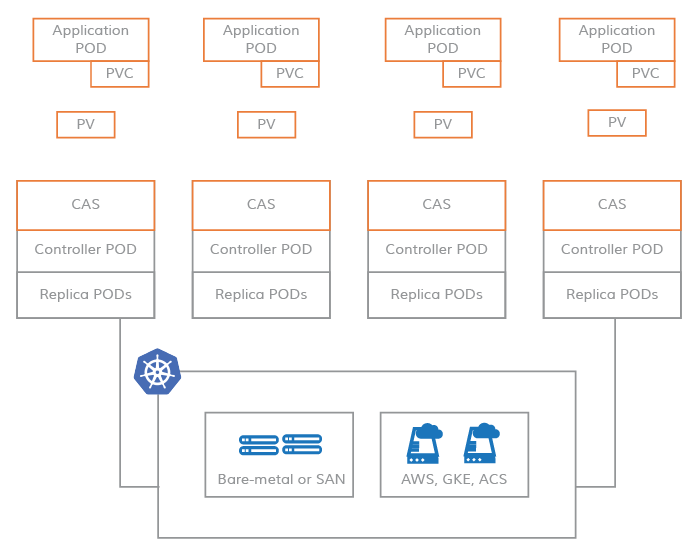
PVs on CAS systems
In contrast, CAS enables you to leverage flexibility and scalability of cloud-native applications. The storage software that defines a Kubernetes PV (Persistent Volume) is based on the micro services architecture. The control plane (storage controller) and the data plane of the storage software (storage replica) are run as Kubernetes Pods and, therefore, enable you to apply all the advantages of being cloud-native to CAS.
Advantages of CAS
Agility
Each storage volume in CAS has a containerized storage controller and corresponding containerized replicas. Hence, maintenance and tuning of the resources around these components are truly agile. The Kubernetes rolling upgrades capability enables seamless upgrades of storage controller and storage replicas. Resources such as CPU and memory, can be tuned using container cGroups.
Granularity of Storage Policies
Containerizing the storage software and dedicating the storage controller to each volume brings maximum granularity in storage policies. With CAS architecture, you can configure all storage policies on a per-volume basis. In addition, you can monitor storage parameters of every volume and dynamically update storage policies to achieve the desired result for each workload. The control of storage throughput, IOPS, and latency increases with this additional level of granularity in the volume storage policies.
Avoids Lock-in
Avoiding cloud vendor lock-in is the common goal for most users and enterprises. This goal has contributed significantly to the adoption of Kubernetes as it is a widely accepted orchestration platform for containers. However, the data of stateful applications remains dependent on the cloud provider and technology. With CAS approach, storage controllers can migrate the data in the background and live migration becomes a fairly simple task. In other words, stateful workloads can be moved from one Kubernetes cluster to another in a non-disruptive way for users.
Cloud Native
CAS containerizes the storage software and uses Kubernetes Custom Resource Definitions (CRDs) to represent the low-level storage resources, such as disks and storage pools. This model enables storage to be integrated into other cloud-native tools seamlessly. The storage resources can be provisioned, monitored, managed using cloud-native tools such as Prometheus, Grafana, Fluentd, Weavescope, Jaeger, and others.
PV is a micro service in CAS
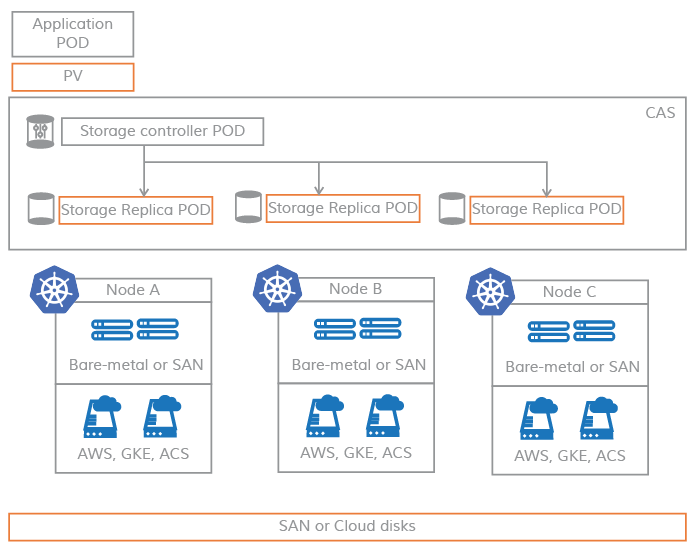
As shown in the above diagram, in CAS architecture, the software of storage controller and replicas are completely micro services based and hence no kernel components are involved. Typically, the storage controller POD is scheduled on the same node as the persistent volume to increase the efficiency and the replica pods can be scheduled anywhere on the cluster nodes. Each replica is configured completely independently from the others using any combination of local disks, SAN disks, and cloud disks. This allows huge flexibility in managing the storage allocation for workloads at scale.
Hyperconverged and not Distributed
CAS architecture does not follow a typical distributed storage architecture with blast radius limitations. With synchronous replication from storage controller onto the storage replicas, the storage becomes highly available. The metadata of volume replicas are not shared among the nodes and is independently managed on every local node. If a node fails, the storage controller, which is a stateless container in this case, is spun on a node where second or third replica is running and data continues to be available. Hence, with CAS there is no blast radius effect that is typically seen in distributed storage systems such as Ceph, Glusterfs, and so on in the event of node failures.
Similar to hyperconverged systems, storage and performance of a volume in CAS is scalable. As each volume is having it's own storage controller, the storage can scale up within the permissible limits of a storage capacity of a node. As the number of container applications increase in a given Kubernetes cluster, more nodes are added, which increases the overall availability of storage capacity and performance, thereby making the storage available to the new application containers. This process is exactly similar to the successful hyperconverged systems like Nutanix.
See Also:
OpenEBS architecture
CAS blog on CNCF
Feedback
Was this page helpful?
Thanks for the feedback. Open an issue in the GitHub repo if you want to report a problem or suggest an improvement. Engage and get additional help on https://kubernetes.slack.com/messages/openebs/.